
From the 3rd to the 5th of April, ContentDB was hit by a Distributed Denial of Service (DDoS) attack, where it received over 5 million requests from 2,200 IP addresses. This blog post shares statistics on the attack and a reflection on how this can be prevented in the future.
Background #
I am the creator and sole maintainer of ContentDB, a website to provide games, mods, and texture packs for the Luanti game-creation platform. This is an open-source hobby project I do in my own time, it’s not-for-profit.
ContentDB is a Python Flask application with a Postgres database. It sits behind nginx to provide caching, rate limiting, and SSL/TLS termination.
ContentDB is hosted on a £16 per month Virtual Private Server (VPS). I use a single Linux VPS because it provides predictable pricing. This is a volunteer and non-profit project; if ContentDB is suddenly hit by a lot of traffic, I would rather that it go offline than send me a huge bill due to cloud hosting.
The attack #
Statistics #
Starting on the 3rd of April, ContentDB received a sustained DDoS attack that took the service offline for 12 hours. It received over 5,000,000 requests from 2,200 unique IP addresses, all registered to BytePlus in Singapore. BytePlus is ByteDance’s cloud platform.
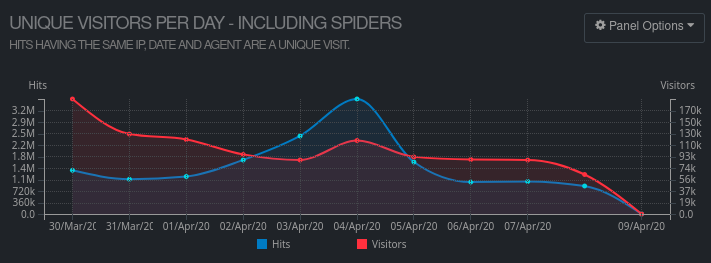
If you filter out cached requests and static files, you end up with the requests that make it to the Python web app:
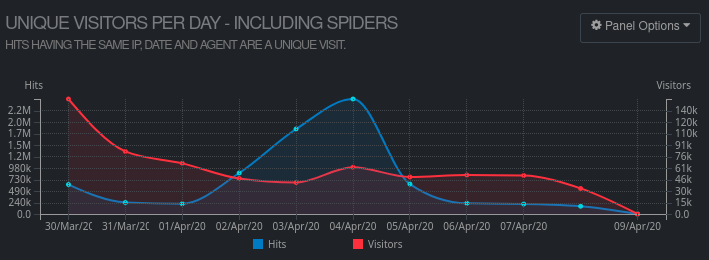
On the peak day of the attack, ContentDB’s Python code received 2,446,000 requests, which is 11x more than the average of 220,000 per day.
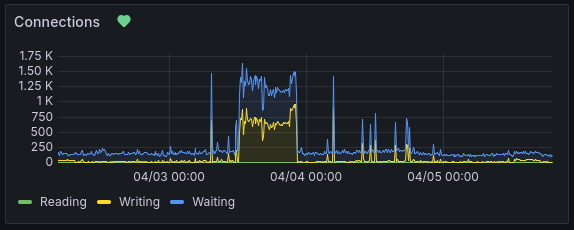
During the attack, there were 1,500 open connections at a time. Typically, there are 150.
Why did ContentDB go offline? #
This is a relatively small attack.
ContentDB has handled comparable levels of traffic increase in the past without going offline. For example, in 2022, Bobicraft posted a YouTube video about Luanti that caused a 10x increase in traffic to ContentDB.
The reason that ContentDB went offline is that this time almost all of the additional traffic was not cached and went to the Python web server. The attack was focused on ContentDB’s search, which is a particularly expensive page.
Looking at the server’s Grafana dashboard, I can see that CPU usage hits a ceiling:
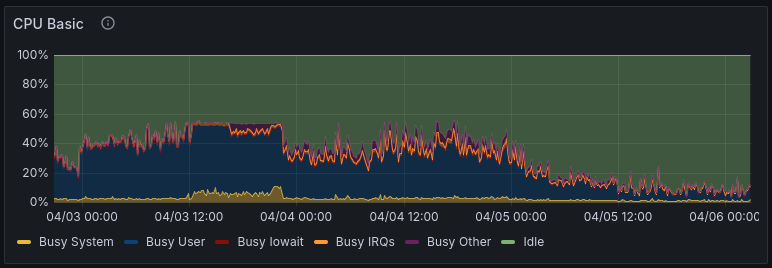
This implies that there were not enough workers running. 50% CPU usage on an 8 core server would be 4 workers maxing out. Guess what, ContentDB uses 4 gunicorn web workers.
Unfortunately, I was on holiday and away from my laptop during the attack so I was unable to perform any mitigating measures.
Package search and tags #
The search page includes links that will add or remove a tag to the search query. These links are marked by “nofollow”, but a misbehaving or malicious crawler could ignore this and get stuck crawling all possible combinations of tags. To protect against this, ContentDB requires users to log in to filter by multiple tags.
However, in this attack, the query string was malformed:
"GET /packages/?random=1&%3Bamp%3Bamp%3Bamp%3Bamp%3Bamp%3Bpage=1&%3Bamp%3Bamp%3Bamp%3Bamp%3Bamp%3Btag=64px&%3Bamp%3Bamp%3Bamp%3Bamp%3Bpage=1&%3Bamp%3Bamp%3Bamp%3Bamp%3Btag=gui&%3Bamp%3Bamp%3Bamp%3Bpage=1&%3Bamp%3Bamp%3Bamp%3Btag=world_tools&%3Bamp%3Bamp%3Bpage=1&%3Bamp%3Bamp%3Btag=building_mechanics&%3Bamp%3Bpage=1&%3Bamp%3Btag=16px&%3Bpage=1&%3Btag=food HTTP/1.1" 200 9670 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36" 8.375
Notice how &tag= has been URL encoded to &%3Btag=. This had the result of
generating a large number of unique URLs without actually searching for multiple
tags, which would have been blocked.
Speculation: was this a targetted attack or a malicious crawler? #
Given the attack pattern, my theory is that this was a crawler scraping ContentDB for training data and getting confused over the search page. Perhaps they were collecting the data to use with gen AI models.
The sheer scale and the fact that the crawler did not identify itself in the user agent leads me to conclude that this was malicious. Even if this was a crawler and not a targetted attack against ContentDB, the behaviour demonstrates malicious intent.
Immediate mitigations #
Stricter validation on the search page #
As mentioned, ContentDB already requires users to be logged in to search for
multiple tags. ContentDB now checks search query arguments better, blocking
incorrectly URL encoded arguments like &%3B.
Alarms and monitoring #
I’ve run Grafana and Prometheus for my services for a while. I also have a status page hosted by uptimerobot to let me know if my services go offline.
I have now set up Grafana alerts to let me know if there is a huge increase in connections or resource usage.
Future plans / options #
Increase the number of workers #
The CPU usage implies that there are not enough web workers running. By increasing the number of workers, ContentDB will be able to handle more traffic.
Improve Python/database performance #
I should look into options to improve the performance of the Python web application, particularly when it comes to reading from the database.
Read replicas and mirrors #
ContentDB is currently a monolithic application hosted on a single server. The most important aspect of ContentDB is the ability to search and install packages inside the client. This is entirely read-only, there’s no reason for this to go offline if the rest of ContentDB goes offline. If the API and uploads were mirrored by other servers, this would improve reliability and availability. If the mirrors were hosted throughout the world it would also improve user experience.
Anubis #
Anubis is a web firewall that can be used to challenge clients and protect against automated attacks. Anubis could be placed in front of just the search page or the entire website.
I’m not a huge fan of Anubis as I think it breaks the open web and results in a worse user experience. However, the impact can be reduced by configuring when it is triggered.
Adopting cloud technology #
The way that companies achieve high availability for millions of users is by using cloud technology to scale services based on demand.
The reason why I have not done this for ContentDB is because it is unpredictable and expensive on a small scale. With a VPS, I have a fixed bill each month. Using cloud technology would also increase the development costs and complexity given that I am one person.
However, as Luanti grows, it may become necessary to take some ideas from cloud technology to allow ContentDB to scale too.
Conclusion #
Whilst it’s not great that ContentDB went down and I received a load of emails from annoyed users whilst on holiday, I am glad that this attack didn’t cost me or Luanti a significant amount of money.
It’s not clear whether this was a targetted attack or a bad crawler. It sucks how these AI companies are externalising their costs onto volunteer open-source projects and generally being bad Internet citizens.
If you’d like to look into the data yourself, much of it is available on my public Grafana instance. But do so quickly as it’ll only be retained for up to 2 months.
Support ContentDB #
ContentDB’s infrastructure costs are paid for by the Luanti non-profit collective. I am the sole maintainer of ContentDB; if you’d like to support or thank me for my time and efforts, I also accept donations.
Comments
As an alternative to anubis consider using a simple cookie, it seems like a lighter solution that might or might not help. fxgn.dev/blog/anubis
Thank you for your work
It is very unlikely that it was a targeted attack or any attack at all. Similar events have been happening at many different websites, ranging from publication databases to personal blogs. Millions of nonsensical, repeated requests from millions (not just thousands) of different IPs. The most likely explanation is the introduction of AI-based scrapers - you can experience this sort of behavior as a client if you give shell access to a cheap AI agent and let it “browse the Internet” for you. LLMs are infamous for getting in loops outputting the same sequence of tokens (and if these tokens are interpreted as “tool call”, it means requesting the same URL in an endless loop). When you multiply this behavior by thousands of users experimenting with this tech and also add some huge companies interested in “intelligently” scraping everything off the Internet into their private storage, this is what you get as a result.
It’s just a new form of robo-spam, which unlike real spam serves very little purpose for the spammer - who can also be rather unaware that they are contributing to it because in their eyes “the AI agent is working”.
Fortunately, so far it is quite simple to fend off by recognizing the request patterns at URL level and just rejecting them wholesale with nginx rules, so that they do not get as far as your real webserver or (worse) database. It becomes very important that your own requests are identifiable (i.e. use CSRF tokens - which is unfortunately more difficult for APIs, use some form of key there which can be public, but does not remain static so that the bots don’t “learn” it).
And of course all these bots are forging User-Agent and ignoring robots.txt completely.
In the speculation section, I concluded that this is most likely a malicious scraper perhaps gathering data for large language models. The fact that it’s not targetted doesn’t mean it’s not an attack. The sheer scale and number of source IPs could just incompetence, but the human-like user agent is malicious. This was an attack on ContentDB and is an ongoing attack on the web.
Originally, the title of this blog post was something like “Luanti ContentDB was attacked by AI scrapers” but I have no evidence for this so I changed it to something more neutral.
I’ve blocked these bots both at the firewall level and the endpoints they were targeting, this, so far, has been very effective.